Why Natural Language Processing is Important
in Data Science and AI
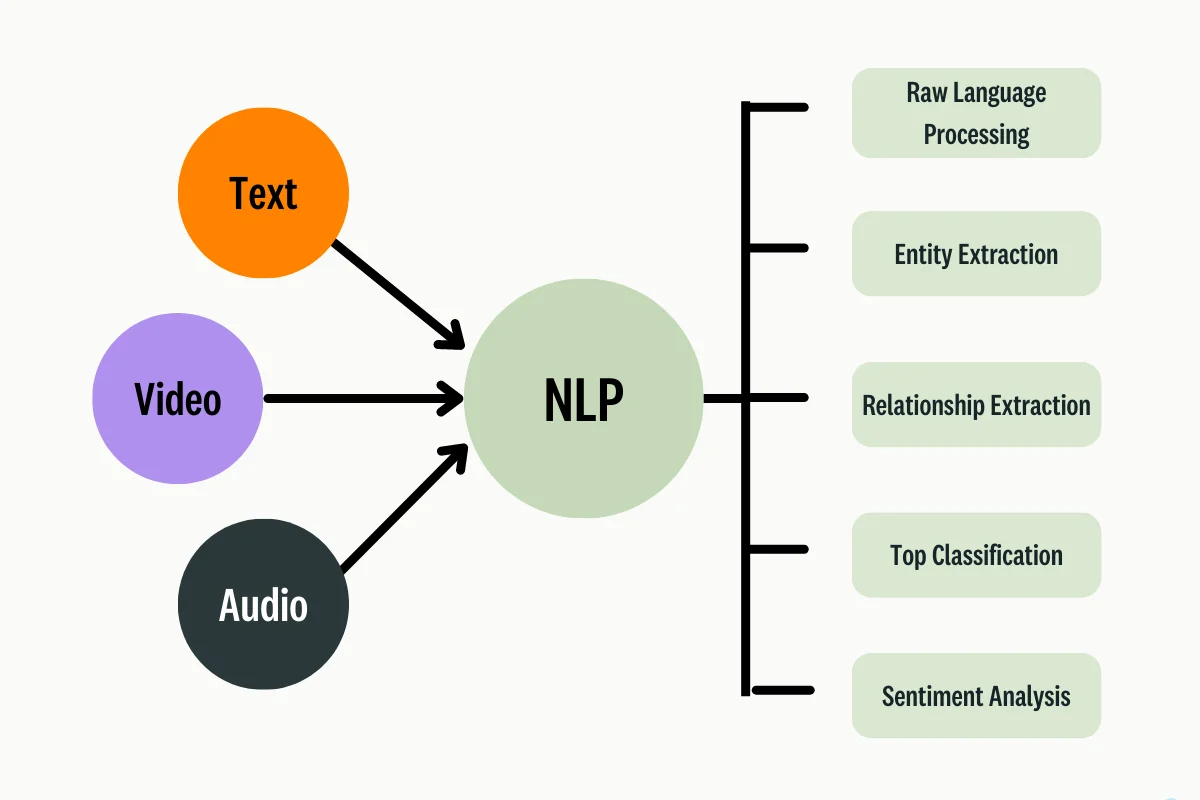
NLP bridges the gap between human language and machines, enabling them to read, understand, and generate text and speech.
It powers essential applications like chatbots, virtual assistants, sentiment analysis, machine translation, and more.